# MyBatis
# 第 1 章 MyBatis 介绍
# 1.1 概述
# 1.1.1 为什么需要 MyBatis
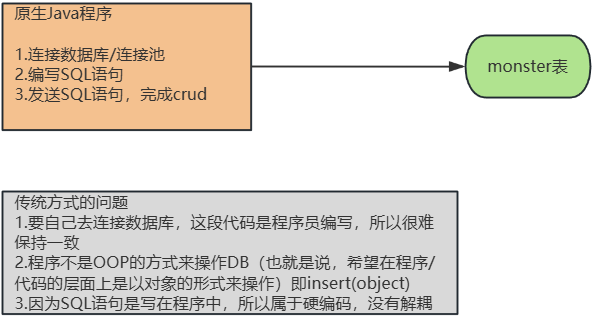
传统的 Java 程序操作 DB 分析
# 1.1.2 基本介绍
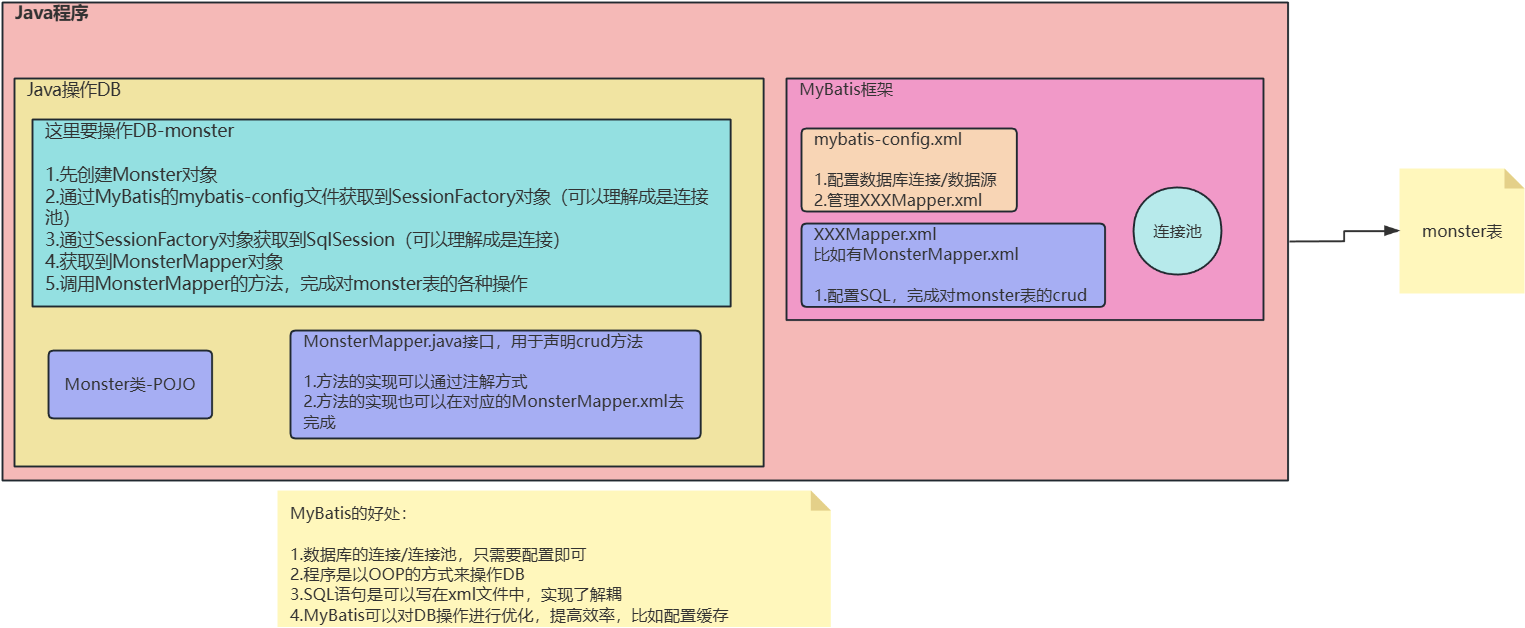
(1)MyBatis 是一个持久层框架
(2)MyBatis 在 Java 和 SQL 之间提供更灵活的映射方案
(3)MyBatis 可以将对数据表的操作(SQL,方法)等直接剥离,写到 XML 配置文件,实现和 Java 代码的解耦
(4)MyBatis 通过 SQL 操作 DB,建库建表的工作还是需要程序员完成
# 1.1.3 MyBatis 工作原理
# 第 2 章 MyBatis 快速入门
# 2.1 需求说明
开发一个 MyBatis 项目,通过 MyBatis 的方式可以完成对 monster 表的 crud 操作
# 2.2 代码实现
SQL
create database mybatis;
use mybatis;
create table monster(
id int not null auto_increment primary key ,
age int not null ,
birthday date default null,
email varchar(255) not null ,
gender tinyint not null ,
name varchar(255) not null ,
salary double not null
);
-- 添加语句,建议表名和字段名带上反引号
insert into monster (age, birthday, email, gender, name, salary) values (10, null, 'hsp@sohu.com', 1, 'kate', 1000);
2
3
4
5
6
7
8
9
10
11
12
13
14
创建 Maven 项目,并引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--
1.将 mybatis 作为父项目管理多个子模块/子项目
2.父项目的完整的坐标 groupId[组织名] + artifactId[项目名]
3.后面该父项目会管理多个子模块/子项目,将来父项目中引入的依赖可以直接给子项目用
-->
<groupId>com.hspedu</groupId>
<artifactId>mybatis</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<modules>
<module>mybatis_quickstart</module>
</modules>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!--加入依赖-->
<dependencies>
<!--MySQL 的依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!--MyBatis 的依赖-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<!--Junit 的依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<!--如果在这写了一个 <scope>test</scope> 表明该 jar 的作用范围在 test 目录下-->
<!--<scope>test</scope>-->
</dependency>
</dependencies>
<!--
在 build 中配置 resources,来防止资源导出失败的问题
报错说找不到什么文件就增加相应配置即可
含义是将 src/main/java 目录及其子目录和 src/main/resources 目录及其子目录的 xml 和 properties 资源文件在 build 项目时,导出到对应的 target 目录下
-->
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
</resource>
</resources>
</build>
</project>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
连接数据库的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<!--配置事务管理器-->
<transactionManager type="JDBC"/>
<!--配置数据源-->
<dataSource type="POOLED">
<!--配置驱动-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<!--
配置连接 MySQL 的 url
jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
(1) jdbc:mysql 协议
(2) 127.0.0.1:3306 指定连接 MySQL 的 ip + port
(3) mybatis 连接的DB
(4) useSSL=true 表示使用安全连接
(5) & 表示一个 & 符号,防止解析错误
(6) useUnicode=true 使用 unicode 作用是防止编码错误
(7) characterEncoding=UTF-8 指定使用 utf-8,防止中文乱码
-->
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!--
这里配置需要关联的 XXXMapper.xml
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
</mappers>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
JavaBean/POJO 对应 monster 表 Monster.java
package com.hspedu.entity;
import java.util.Date;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:45
* @Description: Monster类 和 monster 表对应
* 这是一个普通的 POJO 类
* 使用原生的 SQL 语句查询结果还是要封装成对象
* 实体类属性名和表字段名保持一致
*/
public class Monster {
//属性和表字段有对应关系
//属性
private Integer id;
private Integer age;
private String name;
private String email;
private Date birthday;
private double salary;
private Integer gender;
public Monster() {
}
public Monster(Integer id, Integer age, String name, String email, Date birthday, double salary, Integer gender) {
this.id = id;
this.age = age;
this.name = name;
this.email = email;
this.birthday = birthday;
this.salary = salary;
this.gender = gender;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
@Override
public String toString() {
return "Monster{" +
"id=" + id +
", age=" + age +
", name='" + name + '\'' +
", email='" + email + '\'' +
", birthday=" + birthday +
", salary=" + salary +
", gender=" + gender +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
接口 MonsterMapper.java 用于声明处理 monster 表的方法
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//添加 monster
public void addMonster(Monster monster);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
配置文件 MonsterMapper.xml 用于实现接口里的方法,
(1)增
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
配置 addMonster
id="addMonster" 是接口的方法名
parameterType="com.hspedu.entity.Monster" 传入形参的类型
(#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary}) 是从传入的 monster 对象属性中来的
-->
<insert id="addMonster" parameterType="com.hspedu.entity.Monster">
insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary});
</insert>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
工具类 MyBatisUtils.java
package com.hspedu.util;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 19:03
* @Description: 工具类,可以得到 SqlSession
*/
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
//编写静态代码块,初始化 sqlSessionFactory
static {
try {
//指定资源文件,配置文件 mybatis-config.xml
String resource = "mybatis-config.xml";
//获取到配置文件 mybatis-config.xml 对应的 inputStream
//加载文件时,Resources.getResourceAsStream(resource) 默认到 resources 目录下找文件,映射成运行后的工作目录是在 target 下的 classes 目录下
InputStream resourceAsStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
System.out.println("sqlSessionFactory = " + sqlSessionFactory.getClass());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//编写方法,返回 SqlSession 对象-会话
public static SqlSession getSqlSession() {
return sqlSessionFactory.openSession();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
测试类 MonsterMapperTest.java
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import com.hspedu.util.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Before;
import org.junit.Test;
import java.util.Date;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 19:20
* @Description:
*/
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper = " + monsterMapper.getClass());
}
@Test
public void addMonster() {
for (int i = 0; i < 2; i++) {
Monster monster = new Monster();
monster.setAge(10 + i);
monster.setBirthday(new Date());
monster.setEmail("kate@qq.com");
monster.setGender(1);
monster.setName("松鼠精- " + i);
monster.setSalary(1000 + i * 10);
monsterMapper.addMonster(monster);
System.out.println("添加对象-- " + monster);
}
//如果是增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("保存成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
(2)修改代码可以在代码中从数据表中拿取自增长的 id
修改 MonsterMapper.xml 文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
配置 addMonster
id="addMonster" 是接口的方法名
parameterType="com.hspedu.entity.Monster" 传入形参的类型
(#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary}) 是从传入的 monster 对象属性中来的
-->
<insert id="addMonster" parameterType="com.hspedu.entity.Monster" useGeneratedKeys="true" keyProperty="id">
insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary});
</insert>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
修改 MonsterMapperTest.java 文件
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import com.hspedu.util.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Before;
import org.junit.Test;
import java.util.Date;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 19:20
* @Description:
*/
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper = " + monsterMapper.getClass());
}
@Test
public void addMonster() {
for (int i = 0; i < 2; i++) {
Monster monster = new Monster();
monster.setAge(10 + i);
monster.setBirthday(new Date());
monster.setEmail("kate@qq.com");
monster.setGender(1);
monster.setName("大象精- " + i);
monster.setSalary(1000 + i * 10);
monsterMapper.addMonster(monster);
System.out.println("添加对象-- " + monster);
System.out.println("添加到表中后,自增长的 id = " + monster.getId());
}
//如果是增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("保存成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
(3)删
在 MonsterMapper.java 中增加方法接口
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//添加 monster
public void addMonster(Monster monster);
//根据 id 删除一个 Monster
public void delMonster(Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在 MonsterMapper.xml 中实现方法
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
配置 addMonster
id="addMonster" 是接口的方法名
parameterType="com.hspedu.entity.Monster" 传入形参的类型
(#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary}) 是从传入的 monster 对象属性中来的
-->
<insert id="addMonster" parameterType="com.hspedu.entity.Monster" useGeneratedKeys="true" keyProperty="id">
insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary});
</insert>
<!--实现 delMonster 方法-->
<delete id="delMonster" parameterType="Integer">
delete from monster where id = #{id}
</delete>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
测试
@Test
public void delMonster() {
monsterMapper.delMonster(4);
//如果是增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("删除成功");
}
2
3
4
5
6
7
8
9
10
(4)改
在实现接口的方法时,要指定入参的类型,要写全类名,这样比较长,所以可以在 mybatis-config.xml 中配置,给全类名起个别名
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--给全类名配置别名-->
<typeAliases>
<typeAlias type="com.hspedu.entity.Monster" alias="Monster"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!--配置事务管理器-->
<transactionManager type="JDBC"/>
<!--配置数据源-->
<dataSource type="POOLED">
<!--配置驱动-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<!--
配置连接 MySQL 的 url
jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
(1) jdbc:mysql 协议
(2) 127.0.0.1:3306 指定连接 MySQL 的 ip + port
(3) mybatis 连接的DB
(4) useSSL=true 表示使用安全连接
(5) & 表示一个 & 符号,防止解析错误
(6) useUnicode=true 使用 unicode 作用是防止编码错误
(7) characterEncoding=UTF-8 指定使用 utf-8,防止中文乱码
-->
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!--
这里配置需要关联的 XXXMapper.xml
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
</mappers>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
注意:在mybatis的config.xml配置时的节点顺序为: properties?, settings?, typeAliases?, typeHandlers?, objectFactory?, objectWrapperFactory?, reflectorFactory?, plugins?, environments?, databaseIdProvider?, mappers? 这个顺序的部分节点可以没有,但是节点的顺序必须按照这个顺序,才不会出错
接口 MonsterMapper.java
//修改 Monster
public void updateMonster(Monster monster);
2
实现接口的方法 MonsterMapper.xml
<!--实现 updateMonster 方法
因为在 mybatis-config.xml 中配置给全类名配置了别名,所以这里的全类名可以简写 parameterType="com.hspedu.entity.Monster" -> parameterType="Monster"
-->
<update id="updateMonster" parameterType="Monster">
UPDATE monster set age=#{age}, birthday=#{birthday}, email=#{email}, gender=#{gender}, name=#{name}, salary=#{salary} WHERE id=#{id}
</update>
2
3
4
5
6
测试
@Test
public void updateMonster() {
Monster monster = new Monster();
monster.setAge(50);
monster.setBirthday(new Date());
monster.setEmail("king2@qq.com");
monster.setGender(0);
monster.setName("老鼠精02");
monster.setSalary(20000);
monster.setId(3);
monsterMapper.updateMonster(monster);
//如果是增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("修改成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
(5)查
接口 MonsterMapper.java
//根据 id 查询
public Monster getMonsterById(Integer id);
//查询所有的 Monster
public List<Monster> findAllMonster();
2
3
4
5
实现方法 MonsterMapper.xml
<!--实现 getMonsterById 方法-->
<select id="getMonsterById" resultType="Monster">
SELECT * from monster where id = #{id}
</select>
<!--实现 findAllMonster-->
<select id="findAllMonster" resultType="Monster">
select * from monster
</select>
2
3
4
5
6
7
8
9
测试类
@Test
public void getMonsterById() {
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster = " + monster);
//如果是查,不需要提交事务,但是还是需要关闭连接
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("查询成功");
}
@Test
public void findAllMonster() {
List<Monster> monsters = monsterMapper.findAllMonster();
for (Monster monster : monsters) {
System.out.println("monster- " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("查询成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 2.3 日志输出 - 查看 SQL
(1)在开发 MyBatis 程序时,比如执行测试方法,程序员往往需要查看程序底层发给 MySQL 的 SQL 语句到底长什么样,怎么办?
修改 mybatis-config.xml 加入日志输出配置,方便分析 SQL 语句
# 2.4 课后练习
创建一个 Monk(和尚) 类

# 第 3 章 自己实现 MyBatis 底层机制
封装 Sqlsession 到执行器 + Mapper 接口和 Mapper.xml + MapperBean + 动态代理 Mapper 的方法
# 3.1 MyBatis 整体架构分析
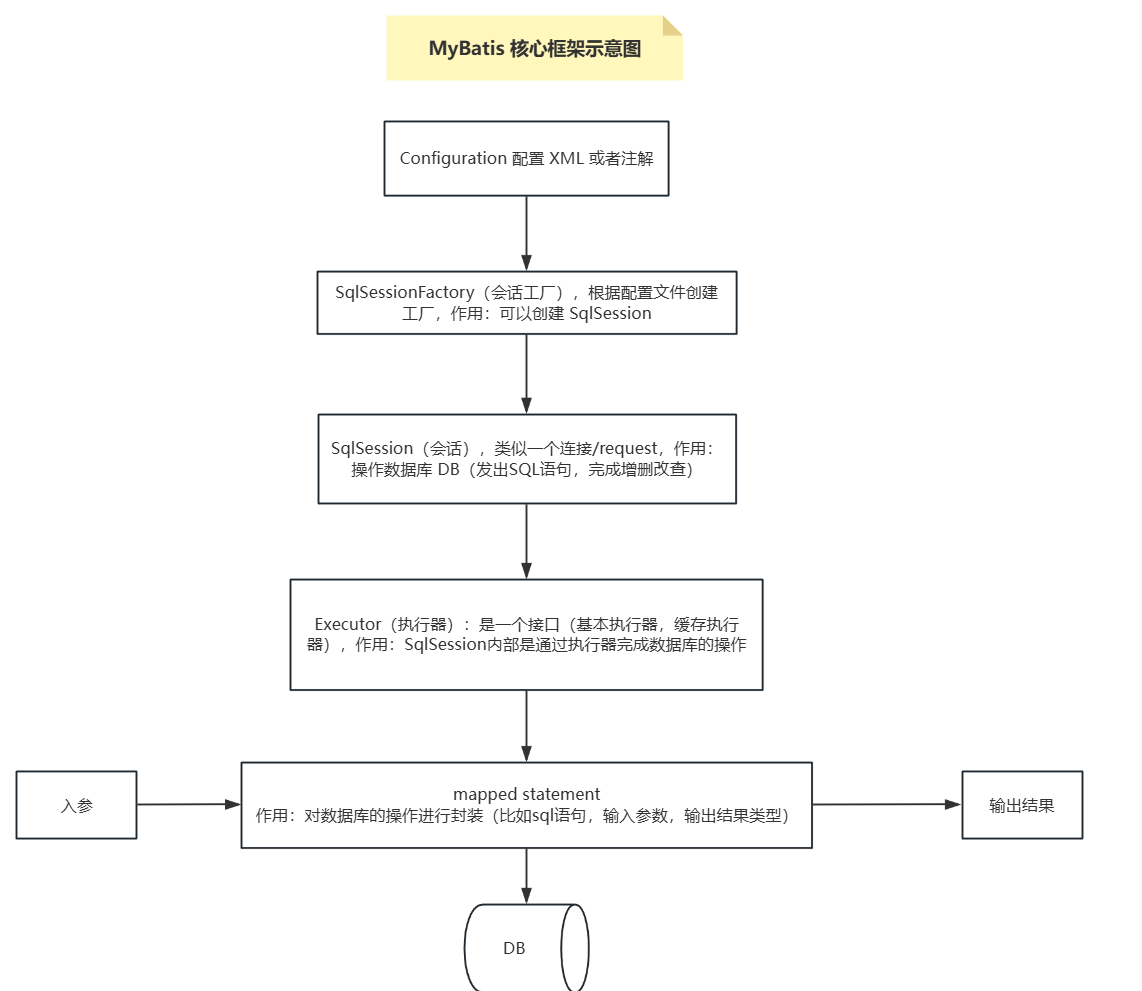
(1)MyBatis 的核心配置文件:
1)mybatis-config.xml:进行全局配置,全局只能有一个这样的配置文件
2)XxxMapper.xml 配置多个 SQL,可以有多个 XxxMapper.xml 配置文件
(2)通过 mybatis-config.xml 配置文件得到 SqlSessionFactory
(3)通过 SqlSessionFactory 得到 SqlSession,用 SqlSession 就可以操作数据
(4)SqlSession 底层是 Executor(执行器)
(5)MappedStatement 是通过 XxxMapper.xml 定义的,生成 statement 对象
(6)参数输入执行并输出结果集,无需手动判断参数类型和参数下标位置,且自动将结果集映射为 Java 对象
# 3.2 搭建 MyBatis 底层机制开发环境
26-47
# 第 4 章 原生的 API & 注解的方式
# 4.1 原生的 API 调用
# 4.1.1 快速入门需求
在前面项目的基础上,将增删改查使用 MyBatis 原生的 API 完成,就是直接通过 SqlSession 接口的方法来完成
# 4.1.2 代码实现
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/5 17:57
* @Description: 使用 MyBatis 原生的 API 操作数据库,使用原生的 API 操作数据库还是需要那个实现了接口的方法的 MyBatisMapper.xml 的配置文件
* 因为原生 API 的底层的 SQL 语句还是走的配置文件里写的 SQL 语句
*/
public class MyBatisNativeTest {
//属性
private SqlSession sqlSession;
//编写方法完成初始化
@Before
public void init() {
//获取到 sqlSession,该 sqlSession 返回的对象是 DefaultSqlSession
sqlSession = MyBatisUtils.getSqlSession();
System.out.println("sqlSession = " + sqlSession.getClass());
}
//使用 sqlSession 原生的 API 调用我们编写的方法
@Test
public void myBatisNativeCrud() {
//添加
Monster monster = new Monster();
monster.setAge(100);
monster.setBirthday(new Date());
monster.setEmail("kate2@qq.com");
monster.setGender(0);
monster.setName("大象精- 100");
monster.setSalary(10000);
int insert = sqlSession.insert("com.hspedu.mapper.MonsterMapper.addMonster", monster);
System.out.println("insert = " + insert);
//删除
int delete = sqlSession.delete("com.hspedu.mapper.MonsterMapper.delMonster", 6);
System.out.println("delete = " + delete);
//修改
Monster monster = new Monster();
monster.setAge(20);
monster.setBirthday(new Date());
monster.setEmail("kate3@qq.com");
monster.setGender(1);
monster.setName("牛魔王- 100");
monster.setSalary(10000);
monster.setId(3); //这个一定要有,如果没有就不知道修改哪个对象
int update = sqlSession.update("com.hspedu.mapper.MonsterMapper.updateMonster", monster);
System.out.println("update = " + update);
//查询
List<Monster> monsters = sqlSession.selectList("com.hspedu.mapper.MonsterMapper.findAllMonster");
for (Monster monster : monsters) {
System.out.println("monster = " + monster);
}
//如果是增删改,需要提交事务和关闭连接,查询需要关闭连接
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 4.2 注解的方式操作
# 4.2.1 快速入门需求
在前面项目的基础上,将增删改查使用 MyBatis 的注解的方式完成
# 4.2.2 代码实现
MonsterAnnotation.java 接口
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/6 11:54
* @Description: 使用注解的方式来配置接口方法
*/
public interface MonsterAnnotation {
//添加 monster
/*
* 使用注解方式配置接口的方法
* xml 的配置方法:
* <insert id="addMonster" parameterType="Monster" useGeneratedKeys="true" keyProperty="id">
insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary});
</insert>
* */
@Insert("insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary})")
public void addMonster(Monster monster);
//根据 id 删除一个 Monster
/*
* xml 文件中的配置
* <delete id="delMonster" parameterType="Integer">
delete from monster where id = #{id}
</delete>
* */
@Delete("delete from monster where id = #{id}")
public void delMonster(Integer id);
//修改 Monster
/*
* <update id="updateMonster" parameterType="Monster">
UPDATE monster set age=#{age}, birthday=#{birthday}, email=#{email}, gender=#{gender}, name=#{name}, salary=#{salary} WHERE id=#{id}
</update>
* */
@Update("UPDATE monster set age=#{age}, birthday=#{birthday}, email=#{email}, gender=#{gender}, name=#{name}, salary=#{salary} WHERE id=#{id}")
public void updateMonster(Monster monster);
//根据 id 查询
/*
* <select id="getMonsterById" resultType="Monster">
SELECT * from monster where id = #{id}
</select>
* */
@Select("SELECT * from monster where id = #{id}")
public Monster getMonsterById(Integer id);
//查询所有的 Monster
/*
* <select id="findAllMonster" resultType="Monster">
select * from monster
</select>
* */
@Select("select * from monster")
public List<Monster> findAllMonster();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
在 mybatis-config.xml 中配置
<!--
这里配置需要关联的 XXXMapper.xml
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
<!--
如果是通过注解的方式可以不再使用 MonsterMapper.xml
但是需要在 mybatis-config.xml 注册含注解的类
如果没有引入,不能使用注解的方式
-->
<mapper class="com.hspedu.mapper.MonsterAnnotation"/>
</mappers>
2
3
4
5
6
7
8
9
10
11
12
测试
public class MonsterAnnotationTest {
//属性
private SqlSession sqlSession;
private MonsterAnnotation monsterAnnotation;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
monsterAnnotation = sqlSession.getMapper(MonsterAnnotation.class);
System.out.println("monsterMapper = " + monsterAnnotation.getClass());
}
@Test
public void addMonster() {
Monster monster = new Monster();
monster.setAge(30);
monster.setBirthday(new Date());
monster.setEmail("kate6@qq.com");
monster.setGender(1);
monster.setName("狐狸精-100");
monster.setSalary(10000);
//使用通过注解方式实现接口方法完成对 DB 的操作
monsterAnnotation.addMonster(monster);
//如果是增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("增加成功");
}
@Test
public void findAllMonster() {
//使用接口配置注解的方式操作 DB
List<Monster> allMonster = monsterAnnotation.findAllMonster();
for (Monster monster : allMonster) {
System.out.println("monster--" + monster);
}
//如果是查询,需要关闭
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("查询成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 4.2.3 注意事项和说明
(1)如果是通过注解的方式,就不再使用 MonsterMapper.xml 文件,但是需要在 mybatis-config.xml 文件中注册含有注解的接口
(2)使用注解方式添加时,如果要返回自增长的 id 值,可以使用 @Option 注解,组合使用
/*
* useGeneratedKeys = true,返回自增的值
* keyProperty = "id",指定此值和传入的对象的哪个属性是对应的,因为 Monster 对象的自增的是 id,所以这里写 id
* keyColumn = "id",指定在表中此字段的名称,比如表中叫 id,这里就写 id
* */
@Insert("insert into monster (age, birthday, email, gender, name, salary) values (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary})")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
public void addMonster(Monster monster);
2
3
4
5
6
7
8
# 第 5 章 mybatis-config.xml 配置文件详解
# 5.1 说明
MyBatis 的核心配置文件(mybatis-config.xml)要配置 jdbc 连接信息,注册 mapper 等,所以需要对这个配置文件有详细的了解
# 5.2 properties 属性
通过该属性,可以指定一个外部的 jdbc.properties 文件,引入我们的 jdbc 连接信息
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入外部的 jdbc.properties-->
<properties resource="jdbc.properties"/>
<!--配置 MyBatis 自带的日志输出-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
<!--给全类名配置别名-->
<typeAliases>
<typeAlias type="com.hspedu.entity.Monster" alias="Monster"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!--配置事务管理器-->
<transactionManager type="JDBC"/>
<!--配置数据源
(1) 使用外部的 properties 文件来设置相关的值
(2) 这个属性文件需要统一的放在 resources 目录下,也就是类加载路径下
-->
<dataSource type="POOLED">
<!--配置驱动-->
<!--<property name="driver" value="com.mysql.cj.jdbc.Driver"/>-->
<property name="driver" value="${jdbc.driver}"/>
<!--
配置连接 MySQL 的 url
jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
(1) jdbc:mysql 协议
(2) 127.0.0.1:3306 指定连接 MySQL 的 ip + port
(3) mybatis 连接的DB
(4) useSSL=true 表示使用安全连接
(5) & 表示一个 & 符号,防止解析错误
(6) useUnicode=true 使用 unicode 作用是防止编码错误
(7) characterEncoding=UTF-8 指定使用 utf-8,防止中文乱码
-->
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.user}"/>
<property name="password" value="${jdbc.pwd}"/>
</dataSource>
</environment>
</environments>
<!--
这里配置需要关联的 XXXMapper.xml
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
<!--
如果是通过注解的方式可以不再使用 MonsterMapper.xml
但是需要在 mybatis-config.xml 注册含注解的类
如果没有引入,不能使用注解的方式
-->
<mapper class="com.hspedu.mapper.MonsterAnnotation"/>
</mappers>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
jdbc.properties
jdbc.driver=com.mysql.cj.jdbc.Driver # jdbc.driver ?????????
jdbc.url=jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
jdbc.user=root
jdbc.pwd=123456
2
3
4
父级的 pom.xml 用于 build 的时候把文件加载到 target 目录中
<!--
在 build 中配置 resources,来防止资源导出失败的问题
报错说找不到什么文件就增加相应配置即可
含义是将 src/main/java 目录及其子目录和 src/main/resources 目录及其子目录的 xml 和 properties 资源文件在 build 项目时,导出到对应的 target 目录下
-->
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
</resource>
</resources>
</build>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 5.3 settings 全局参数定义
这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。 下表描述了设置中各项设置的含义、默认值等
# 5.4 typeAliases 别名处理器
(1)别名是为 Java 类型命名一个短名字,它只和 XML 配置有关,用来减少类名重复的部分
(2)如果指定了别名,我们的 MapperXxx.xml 文件就可以做相应的简化处理
(3)注意指定别名后,还是可以使用全名的
mybatis-config.xml
<!--给全类名配置别名-->
<typeAliases>
<!--<typeAlias type="com.hspedu.entity.Monster" alias="Monster"/>-->
<!--如果一个包下有很多的类,我们可以直接引入包名,这样该包下面的所有类名可以直接使用,就不用写全类名了-->
<package name="com.hspedu.entity"/>
</typeAliases>
2
3
4
5
6
# 5.5 typeHandlers 类型处理器
(1)用于 Java 类型和 JDBC 类型映射
(2)MyBatis 的映射基本已经满足,不太需要重新定义
(3)这个使用默认即可,也就是 MyBatis 会自动的将 Java 和 JDBC 类型进行转换
# 5.6 environments 环境
# 第 6 章 XxxMapper.xml - SQL 映射文件
# 6.1 XxxMapper.xml - 基本介绍
(1)MyBatis 真正强大的在于它的语句映射(在 XxxMapper.xml 配置),由于它的异常强大,如果拿它跟具有相同功能的 JDBC 代码进行对比,会发现省掉了将近 95% 的代码,MyBatis 致力于减少使用成本,让用户更专注于 SQL 代码
(2)SQL 映射文件常用的几个顶级元素(应按照被定义的顺序列出):
cache - 该命名空间的缓存配置
cache-ref - 引用其它命名空间的缓存配置
resultMap - 描述如何从数据库结果集中加载对象,是最复杂也是最强大的元素
parameterType - 将会传入这条语句的参数的类全限定名或别名
sql - 可被其它语句引用的可重用语句块
insert - 映射插入语句
update - 映射更新语句
delete - 映射删除语句
select - 映射查询语句
# 6.2 XxxMapper.xml - 详细说明
# 6.2.1 新建 Module:xml-mapper
(1)在原来的项目中,新建 xml-mapper 项目演示 xml 映射器的使用
(2)新建 Module 后,先创建需要的包,再将需要的文件/资源拷贝过来(这里拷贝 Monster.java、resources/jdbc.properties 和 mybatis-config.xml)
# 6.2.2 基本使用
(1)insert、delete、update、select 这个在前面用过,分别对应增删改查的方法和 SQL 语句的映射
(2)如何获取到刚刚添加的 Monster 对象的 id 主键(前面也使用过)
# 6.2.3 parameterType(输入参数类型)
(1)传入简单类型,比如按照 id 查 Monster
(2)传入 POJO 类型,查询时需要有多个筛选条件
(3)当有多个条件时,传入的参数就是 POJO 类型的 Java 对象,比如这里的 Monster 对象
(4)当传入的参数类是 String 时,也可以使用 ${} 来接收参数
案例1:查询 id = 1 或者 name = '白骨精' 的妖怪
MonsterMapper.java
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//通过 id 或者 名字查询
public List<Monster> findMonsterByNameORId(Monster monster);
//查询名字中含 '精' 的妖怪
public List<Monster> findMonsterByName(String name);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
通过 id 或者 名字查询
配置实现 public List<Monster> findMonsterByNameORId(Monster monster);
parameterType="Monster" 这里能只写类名而不用写全类名是因为在 mybatis-config.xml 中配置了可以简写
id = #{id} 前面的 id 是表的字段名,#{id} 中的 id 是传入的 Monster 对象的属性名
-->
<select id="findMonsterByNameORId" parameterType="Monster" resultType="Monster">
select * from monster where id = #{id} or name = #{name}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
MonsterMapperTest.java
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper = " + monsterMapper.getClass());
}
@Test
public void findMonsterByNameORId() {
Monster monster = new Monster();
monster.setId(1);
monster.setName("牛魔王- 100");
List<Monster> monsters = monsterMapper.findMonsterByNameORId(monster);
for (Monster m : monsters) {
System.out.println("m- " + m);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
案例2:查询 name 中包含 '精' 的妖怪
MonsterMapper.java
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//通过 id 或者 名字查询
public List<Monster> findMonsterByNameORId(Monster monster);
//查询名字中含 '精' 的妖怪
public List<Monster> findMonsterByName(String name);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
通过 id 或者 名字查询
配置实现 public List<Monster> findMonsterByNameORId(Monster monster);
parameterType="Monster" 这里能只写类名而不用写全类名是因为在 mybatis-config.xml 中配置了可以简写
id = #{id} 前面的 id 是表的字段名,#{id} 中的 id 是传入的 Monster 对象的属性名
-->
<select id="findMonsterByNameORId" parameterType="Monster" resultType="Monster">
select * from monster where id = #{id} or name = #{name}
</select>
<!--
配置实现 public List<Monster> findMonsterByName(String name);
查询名字中含 '精' 的妖怪,是模糊查询
模糊查询取值需要使用 ${value} 进行取值
-->
<select id="findMonsterByName" parameterType="String" resultType="Monster">
select * from monster where name like '%${name}%'
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
MonsterMapperTest.java
@Test
public void findMonsterByName() {
List<Monster> monsters = monsterMapper.findMonsterByName("精");
for (Monster monster : monsters) {
System.out.println("monster-- " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
# 6.2.4 传入和返回的参数是 HashMap(重点)
(1)传入的参数是 HashMap 会更加灵活,比如可以灵活的增加查询的属性,而不受限于 Monster 这个 POJO 属性本身,因为传入的参数是 Monster 对象时,只能查询 Monster 属性里有的,其它的就不能查
(2)演示如何遍历一个 List<Map<String, Object>> 的数据类型
(3)实例 1:声明一个方法,按传入参数是 HashMap 的方法,查询 id > 10 并且 salary > 40 的所有妖怪
MonsterMapper.java
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//通过 id 或者 名字查询
public List<Monster> findMonsterByNameORId(Monster monster);
//查询名字中含 '精' 的妖怪
public List<Monster> findMonsterByName(String name);
//查询 id > 10 并且 salary > 40 的所有妖怪,要求传入的参数是 HashMap
public List<Monster> findMonsterByIdAndSalary_ParameterHashMap(Map<String, Object> map);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
通过 id 或者 名字查询
配置实现 public List<Monster> findMonsterByNameORId(Monster monster);
parameterType="Monster" 这里能只写类名而不用写全类名是因为在 mybatis-config.xml 中配置了可以简写
id = #{id} 前面的 id 是表的字段名,#{id} 中的 id 是传入的 Monster 对象的属性名
-->
<select id="findMonsterByNameORId" parameterType="Monster" resultType="Monster">
select * from monster where id = #{id} or name = #{name}
</select>
<!--
配置实现 public List<Monster> findMonsterByName(String name);
查询名字中含 '精' 的妖怪,是模糊查询
模糊查询取值需要使用 ${value} 进行取值
-->
<select id="findMonsterByName" parameterType="String" resultType="Monster">
select * from monster where name like '%${name}%'
</select>
<!--
配置实现 public List<Monster> findMonsterByIdAndSalary_ParameterHashMap(Map<String, Object> map);
如果是以 map 形式传入参数,当这样写时 id > #{id} 表示传入的 map 中的 k-v 中的 k 的名字是 id
-->
<select id="findMonsterByIdAndSalary_ParameterHashMap" parameterType="map" resultType="Monster">
select * from monster where id > #{id} and salary > #{salary}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
MonsterMapperTest.java
@Test
public void findMonsterByIdAndSalary_ParameterHashMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("id", 3);
map.put("salary", 40);
List<Monster> monsters = monsterMapper.findMonsterByIdAndSalary_ParameterHashMap(map);
for (Monster monster : monsters) {
System.out.println("monster == " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
(4)案例 2:传入和返回的类型都是 HashMap:将上面的方法的返回参数改成也以 HashMap 的类型返回
MonsterMapper.java
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/4 17:51
* @Description:
* 这是一个接口
* 该接口用于声明操作 monster 表的方法
* 这些方法可以通过注解或者 xml 文件来实现
*/
public interface MonsterMapper {
//通过 id 或者 名字查询
public List<Monster> findMonsterByNameORId(Monster monster);
//查询名字中含 '精' 的妖怪
public List<Monster> findMonsterByName(String name);
//查询 id > 10 并且 salary > 40 的所有妖怪,要求传入的参数是 HashMap
public List<Monster> findMonsterByIdAndSalary_ParameterHashMap(Map<String, Object> map);
//查询 id > 10 并且 salary > 40 的所有妖怪,要求传入的参数是 HashMap
public List<Map<String, Object>> findMonsterByIdAndSalary_ParameterHashMap_ReturnHashMap(Map<String, Object> map);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
通过 id 或者 名字查询
配置实现 public List<Monster> findMonsterByNameORId(Monster monster);
parameterType="Monster" 这里能只写类名而不用写全类名是因为在 mybatis-config.xml 中配置了可以简写
id = #{id} 前面的 id 是表的字段名,#{id} 中的 id 是传入的 Monster 对象的属性名
-->
<select id="findMonsterByNameORId" parameterType="Monster" resultType="Monster">
select * from monster where id = #{id} or name = #{name}
</select>
<!--
配置实现 public List<Monster> findMonsterByName(String name);
查询名字中含 '精' 的妖怪,是模糊查询
模糊查询取值需要使用 ${value} 进行取值
-->
<select id="findMonsterByName" parameterType="String" resultType="Monster">
select * from monster where name like '%${name}%'
</select>
<!--
配置实现 public List<Monster> findMonsterByIdAndSalary_ParameterHashMap(Map<String, Object> map);
如果是以 map 形式传入参数,当这样写时 id > #{id} 表示传入的 map 中的 k-v 中的 k 的名字是 id
-->
<select id="findMonsterByIdAndSalary_ParameterHashMap" parameterType="map" resultType="Monster">
select * from monster where id > #{id} and salary > #{salary}
</select>
<!--
配置实现public List<Map<String, Object>> findMonsterByIdAndSalary_ParameterHashMap_ReturnHashMap(Map<String, Object> map);
要求 id > 10 并且 salary 大于 40,要求传入的参数和返回的是 HashMap
-->
<select id="findMonsterByIdAndSalary_ParameterHashMap_ReturnHashMap" parameterType="map" resultType="map">
select * from monster where id > #{id} and salary > #{salary}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
MonsterMapperTest.java
@Test
public void findMonsterByIdAndSalary_ParameterHashMap_ReturnHashMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("id", 3);
map.put("salary", 40);
List<Map<String, Object>> monsterList = monsterMapper.findMonsterByIdAndSalary_ParameterHashMap_ReturnHashMap(map);
//取出返回的结果,以 map 的形式取出
//遍历 map
for (Map<String, Object> monsterMap : monsterList) {
//System.out.println("monsterMap = " + monsterMap);
//遍历 monsterMap,取出属性和对应值
/*Set<String> keys = monsterMap.keySet();
for (String key : keys) {
System.out.println(key + "=>" + monsterMap.get(key));
}*/
for (Map.Entry<String, Object> entry : monsterMap.entrySet()) {
System.out.println(entry.getKey() + "==>" + entry.getValue());
}
System.out.println("&&&&&&&&&&&&&&&&&&");
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 6.2.5 resultMap(结果集映射)
# 6.2.5.1 应用实例
当实体类的属性和表的字段名字不一致时,可以通过 resultMap 进行映射,从而屏蔽实体类属性名和表的字段名的不同
案例一:插入操作
POJO:User.java
public class User {
private Integer user_id;
private String username;
private String useremail;
public Integer getUser_id() {
return user_id;
}
public void setUser_id(Integer user_id) {
this.user_id = user_id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getUseremail() {
return useremail;
}
public void setUseremail(String useremail) {
this.useremail = useremail;
}
@Override
public String toString() {
return "User{" +
"user_id=" + user_id +
", username='" + username + '\'' +
", useremail='" + useremail + '\'' +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
接口:UserMapper.java
public interface UserMapper {
//添加方法
public void addUser(User user);
//查询所有的 User
public List<User> findAllUser();
}
2
3
4
5
6
7
实现接口:UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.UserMapper">
<!--
配置实现public void addUser(User user);
完成添加用户的任务,注意这里 user 属性和表的字段名不一致
-->
<insert id="addUser" parameterType="User">
insert into user (user_email, user_name) value (#{useremail}, #{username});
</insert>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
测试:UserMapperTest.java
public class UserMapperTest {
//属性
private SqlSession sqlSession;
private UserMapper userMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 UserMapper 对象
userMapper = sqlSession.getMapper(UserMapper.class);
System.out.println("userMapper = " + userMapper.getClass());
}
@Test
public void t1() {
System.out.println("测试成功");
}
@Test
public void addUser() {
User user = new User();
user.setUsername("jack");
user.setUseremail("jack@qq.com");
userMapper.addUser(user);
//如果是增删改,需要提交
if(sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("操作成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
这里注意要在 mybatis-config.xml 中配置引入需要关联的 XxxMapper.xml,不然会报错:Type interface UserMapper is not known to the MapperRegistry.
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入外部的 jdbc.properties-->
<properties resource="jdbc.properties"/>
<!--配置 MyBatis 自带的日志输出-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
<!--给全类名配置别名-->
<typeAliases>
<!--<typeAlias type="com.hspedu.entity.Monster" alias="Monster"/>-->
<!--如果一个包下有很多的类,我们可以直接引入包名,这样该包下面的所有类名可以直接使用,就不用写全类名了-->
<package name="com.hspedu.entity"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!--配置事务管理器-->
<transactionManager type="JDBC"/>
<!--配置数据源
(1) 使用外部的 properties 文件来设置相关的值
(2) 这个属性文件需要统一的放在 resources 目录下,也就是类加载路径下
-->
<dataSource type="POOLED">
<!--配置驱动-->
<!--<property name="driver" value="com.mysql.cj.jdbc.Driver"/>-->
<property name="driver" value="${jdbc.driver}"/>
<!--
配置连接 MySQL 的 url
jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
(1) jdbc:mysql 协议
(2) 127.0.0.1:3306 指定连接 MySQL 的 ip + port
(3) mybatis 连接的DB
(4) useSSL=true 表示使用安全连接
(5) & 表示一个 & 符号,防止解析错误
(6) useUnicode=true 使用 unicode 作用是防止编码错误
(7) characterEncoding=UTF-8 指定使用 utf-8,防止中文乱码
-->
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.user}"/>
<property name="password" value="${jdbc.pwd}"/>
</dataSource>
</environment>
</environments>
<!--
这里配置需要关联的 XXXMapper.xml
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
<mapper resource="com/hspedu/mapper/UserMapper.xml"/>
</mappers>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
案例二:查询
UserMapper.java
public interface UserMapper {
//添加方法
public void addUser(User user);
//查询所有的 User
public List<User> findAllUser();
}
2
3
4
5
6
7
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.UserMapper">
<!--
配置实现public void addUser(User user);
完成添加用户的任务,注意这里 user 属性和表的字段名不一致
-->
<insert id="addUser" parameterType="User">
insert into user (user_email, user_name) value (#{useremail}, #{username});
</insert>
<!--
配置实现方法 public List<User> findAllUser();
返回所有的 user 信息
这里查询的时候,属性名和字段名是不一致的,看看会出现什么样的问题:如果对象属性名和表字段名相同时,就会取到值,如果不相同,就会是默认值,就是 null
这里可以使用 resultMap 来解决这个问题
其中:
标签 resultMap 表示我们要定义一个 resultMap
id="findAllUserMap" 中 id 是程序员指定的 resultMap 的 id,后面要通过 id 进行引用并使用它
type="User" 就是需要返回的对象类型,本应该写全类名,但是在配置文件中配置了简写,所以这里可以简写
<result column="user_email" property="useremail"/> 中,column="user_email" 是表的字段名, property="useremail" 是对象属性名,表示把 user_email 映射成 useremail
-->
<resultMap id="findAllUserMap" type="User">
<result column="user_email" property="useremail"/>
<result column="user_name" property="username"/>
</resultMap>
<select id="findAllUser" resultMap="findAllUserMap">
select * from user;
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
UserMapperTest.java
@Test
public void findAllUser() {
List<User> users = userMapper.findAllUser();
for (User user : users) {
System.out.println("user = " + user);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
# 6.2.5.2 注意事项和细节
(1)解决表字段和对象属性名不一致的情况,也支持使用字段别名,但是不推荐使用,用 resultMap 更好
(2)如果是 MyBatis-Plus 处理就比较简单,可以使用注解 @TableField 来解决实体字段名和表字段名不一致的问题,还可以使用 @TableName 来解决实体类名和表名不一致的问题
# 第 7 章 动态 SQL 语句 - 更复杂的查询业务需求
# 7.1 动态 SQL - 基本介绍
动态 SQL_MyBatis中文网 (opens new window)
# 7.1.1 为什么需要动态 SQL
(1)动态 SQL 是 MyBatis 的强大特性之一
(2)使用 JDBC 或其它类似的框架,根据不同条件拼接 SQL 语句非常麻烦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号等
(3)SQL 映射语句中的强大的动态 SQL 语言,可以很好的解决这个问题
# 7.1.2 基本介绍
(1)在一个实际的项目中,sql 语句往往是比较复杂的,为了满足更加复杂的业务需求,MyBatis 的设计者提供了动态生成 SQL 的功能
(2)比如我们查询 Monster 时,如果程序员输入的 age 不大于 0,我们的 sql 语句就不带 age;更新 Monster 对象时,没有设置新的属性值,就保持原来的值,设置了新的值才更新
(3)从上面的需求可以看出,有时我们在生成 sql 语句时,在同一个方法中,还要根据不同的情况生成不同的 sql 语句,解决方案就是使用 MyBatis 提供的动态 SQL 机制
(4)动态 SQL 常用标签:动态 SQL 提供了如下几种常用的标签,类似我们 Java 的控制语句:
1)if 【判断】
2)where 【拼接 where 子句】
3)choose/when/otherwise 【类似 Java 的 switch 语句,注意是单分支】
4)foreach 【类似 in】
5)trim 【替换关键字/定制元素的功能】
6)set 【在 update 的 set 中,可以保证进入 set 标签的属性被修改,而没有进入 set 的,保持原来的值】
# 7.2 动态 SQL - 案例演示
# 7.2.1 新建 Module:dynamic-sql
(1)在原来的项目中,新建 dynamic-sql 项目演示动态 SQL 的使用
(2)新建 Module 后,先创建需要的包,再将需要的文件/资源拷贝过来(这里拷贝 Monste.java、resources/jdbc.properties 和 mybatis-config.xml)
(3)创建 MonsterMapper.java、MonsterMapper.xml 和 MonsterMapperTest.java
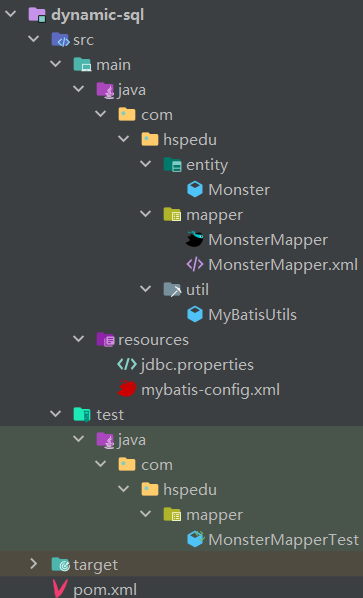
# 7.2.2 if 标签应用实例
需求:查询 age 大于 10 的所有妖怪,如果程序员输入的 age 不大于 0,则输出所有的妖怪
接口 MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
/*
@param使用与否的区别:
不使用@param:
只能有一个参数,该参数只能为Javabean类型(即参数只能是对象);sql语句只能使用 # 获取参数值,在SQL语句中,可以直接获取对象的字段,而不需要使用“对象.字段”的形式(这样使用反而会报错)
使用@param:
可以有多个参数,参数类型没有限制;sql语句可以使用 # 或者 $ 获取参数值,若参数为对象,在SQL语句中,需要使用“对象.字段”的形式获取对象的字段值
*/
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
}
2
3
4
5
6
7
8
9
10
11
实现接口 MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
配置实现方法 public List<Monster> findMonsterByAge(Integer age);
查询 age 大于 10 的所有妖怪,如果程序员输入的 age 不大于 0,则输出所有的妖怪
如果按照以前的方式来配置会有什么问题:无法表达 程序员输入的 age 不大于 0,则输出所有的妖怪 这句判断
但是在使用动态 SQL 时在 test="#{age} >= 0" 中的引号中的 #{age} 不能被识别出来,
解决办法就是在 public List<Monster> findMonsterByAge(Integer age); 中的入参使用注解 @Param
public List<Monster> findMonsterByAge(@Param(value="age) Integer age); 再把 test="#{age} >= 0" 改成 test="age >= 0",这样就能识别出来了
其中 @Param(value="age) 中的 age 要和 test="age >= 0" 中的 age 保持一致
select * from monster where 1 = 1 表示查询所有
-->
<select id="findMonsterByAge" resultType="Monster" parameterType="Integer">
select * from monster where 1 = 1
<if test="age >= 0">
and age > #{age};
</if>
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
测试类 MonsterMapperTest.java
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper = " + monsterMapper.getClass());
}
@Test
public void t1() {
System.out.println("ok");
}
@Test
public void findMonsterByAge() {
List<Monster> monsters = monsterMapper.findMonsterByAge(10);
for (Monster monster : monsters) {
System.out.println("monster = " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 7.2.3 where 标签应用实例
查询 id 大于 1 的,并且名字是 "牛魔王-100" 的所有妖怪,注意如果名字为空或者输入的 id 小于 0,则不拼接 SQL 语句(如果名字为空,则不带名字条件,如果输入的 id 小于 0,就不带 id 的条件)
MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
//根据 id 和名字来查询结果
public List<Monster> findMonsterByIdAndName(Monster monster);
}
2
3
4
5
6
MonsterMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--
配置实现方法 public List<Monster> findMonsterByAge(Integer age);
查询 age 大于 10 的所有妖怪,如果程序员输入的 age 不大于 0,则输出所有的妖怪
如果按照以前的方式来配置会有什么问题:无法表达 程序员输入的 age 不大于 0,则输出所有的妖怪 这句判断
但是在使用动态 SQL 时在 test="#{age} >= 0" 中的引号中的 #{age} 不能被识别出来,
解决办法就是在 public List<Monster> findMonsterByAge(Integer age); 中的入参使用注解 @Param
public List<Monster> findMonsterByAge(@Param(value="age) Integer age); 再把 test="#{age} >= 0" 改成 test="age >= 0",这样就能识别出来了
其中 @Param(value="age) 中的 age 要和 test="age >= 0" 中的 age 保持一致
select * from monster where 1 = 1 表示查询所有
-->
<select id="findMonsterByAge" resultType="Monster" parameterType="Integer">
select * from monster where 1 = 1
<if test="age >= 0">
and age > #{age};
</if>
</select>
<!--
配置实现方法 public List<Monster> findMonsterByIdAndName(Monster monster);
在 test 表达式中,如果入参是对象,则可以直接使用对象的属性名即可,不需要使用 #{},但是要拼接的 SQL 语句要使用 #{}
where 标签会在组织动态 SQL 时,加上 where
MyBatis 底层会自动的去掉多余的 and
-->
<select id="findMonsterByIdAndName" parameterType="Monster" resultType="Monster">
select * from monster
<where>
<if test="id >= 0">
and id > #{id}
</if>
<if test="name != null and name != ''">
and name = #{name}
</if>
</where>
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
MonsterMapperTest.java
@Test
public void findMonsterByIdAndName() {
Monster monster = new Monster();
monster.setId(1);
monster.setName("牛魔王-100");
List<Monster> monsters = monsterMapper.findMonsterByIdAndName(monster);
for (Monster m : monsters) {
System.out.println("m = " + m);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 7.2.4 choose/when/otherwise 应用实例
需求:
(1)如果给的 name 不为空,就按名字查询妖怪
(2)如果指定的 id > 0,就按 id 来查询妖怪
(3)如果前面两个条件都不满足,就默认查询 salary > 100的
(4)要求使用 choose/when/otherwise 标签实现,传入参数要求使用 Map
MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
//根据 id 和名字来查询结果
public List<Monster> findMonsterByIdAndName(Monster monster);
//测试 choose 标签的使用
public List<Monster> findMonsterByIdOrName_choose(Map<String, Object> map);
}
2
3
4
5
6
7
8
MonsterMapper.xml
<!--
配置实现方法 public List<Monster> findMonsterByIdOrName_choose(Map<String, Object> map);
-->
<select id="findMonsterByIdOrName_choose" parameterType="map" resultType="Monster">
select * from monster
<choose>
<when test="name != null and name != ''">
where name = #{name}
</when>
<when test="id > 0">
where id > #{id}
</when>
<otherwise>
where salary > 100
</otherwise>
</choose>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
MonsterMapperTest.java
@Test
public void findMonsterByIdOrName_choose() {
Map<String, Object> map = new HashMap<>();
map.put("name", "牛魔王-100");
List<Monster> monsters = monsterMapper.findMonsterByIdOrName_choose(map);
for (Monster monster : monsters) {
System.out.println("monster = " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 7.2.5 forEach 标签应用实例
需求:查询 id 为 20,22,34 的妖怪
MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
//根据 id 和名字来查询结果
public List<Monster> findMonsterByIdAndName(Monster monster);
//测试 choose 标签的使用
public List<Monster> findMonsterByIdOrName_choose(Map<String, Object> map);
//测试 foreach 标签的使用
public List<Monster> findMonsterById_forEach(Map<String, Object> map);
}
2
3
4
5
6
7
8
9
10
MonsterMapper.xml
<!--
配置实现 public List<Monster> findMonsterById_forEach(Map<String, Object> map);
查询 id 为 10,12,14 的妖怪
根据需求,条件要放在 list 集合中
所以入参传参时要传 k-v,对应:ids - [10,12,14]
原本的 SQL 语句 select * from monster where id in (10, 12, 14)
-->
<select id="findMonsterById_forEach" parameterType="map" resultType="Monster">
select * from monster
<!--
<foreach></foreach> 中:
collection="ids" 对应入参 map 的 key,即 ids
item="id" 在遍历 ids 集合时,每次取出的值对应的变量名是 id
open="(" 表示 SQL语句中 (10, 12, 14) 的第一个 (
separator="," 表示遍历出来的多个值以 , 分隔
close=")" 表示 SQL语句中 (10, 12, 14) 的最后一个 (
#{id} 对应的是 item="id"
-->
<if test="ids != null and ids != ''">
<where>
id in
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</where>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
MonsterMapperTest.java
@Test
public void findMonsterById_forEach() {
Map<String, Object> map = new HashMap<>();
map.put("ids", Arrays.asList(10, 12, 14));
List<Monster> monsters = monsterMapper.findMonsterById_forEach(map);
for (Monster monster : monsters) {
System.out.println("monster = " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
# 7.2.6 trim 标签应用实例【使用较少】
trim 可以替换一些关键字,要求:按名字和年龄查询妖怪,如果 sql 语句开头有 and | or 就替换成 where
MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
//根据 id 和名字来查询结果
public List<Monster> findMonsterByIdAndName(Monster monster);
//测试 choose 标签的使用
public List<Monster> findMonsterByIdOrName_choose(Map<String, Object> map);
//测试 foreach 标签的使用
public List<Monster> findMonsterById_forEach(Map<String, Object> map);
//trim 标签的使用
public List<Monster> findMonsterByName_Trim(Map<String, Object> map);
}
2
3
4
5
6
7
8
9
10
11
12
MonsterMapper.xml
<!--
配置实现方法 public List<Monster> findMonsterByName_Trim(Map<String, Object> map);
按名字和年龄查询妖怪,如果 sql 语句开头有 and | or 就替换成 where
传统方式:使用 where 标签实现,where 标签的功能 [加入 where 同时会去掉多余的 and]
<select id="findMonsterByName_Trim" parameterType="map" resultType="Monster">
select * from monster
<where>
<if test="name != null and name != ''">
and name = #{name}
</if>
<if test="age != null and age != ''">
and age > #{age}
</if>
</where>
</select>
但是 where 的功能是若子句的开头为 “AND” 或 “OR”,where 元素会将它们去除,但是当开头不是 “AND” 或 “OR”,而是别的的时候怎么办?
可以通过自定义 trim 元素来定制 where 元素的功能
<trim prefix="where" prefixOverrides="and|or|hsp"> 表示会带上 where 关键字并且当子句的开头是 “AND” 或 “OR” 或 hsp 时,就去除
-->
<select id="findMonsterByName_Trim" parameterType="map" resultType="Monster">
select * from monster
<trim prefix="where" prefixOverrides="and|or|hsp">
<if test="name != null and name != ''">
hsp name = #{name}
</if>
<if test="age != null and age != ''">
and age > #{age}
</if>
</trim>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
MonsterMapperTest.java
@Test
public void findMonsterByName_Trim() {
Map<String, Object> map = new HashMap<>();
map.put("name", "牛魔王-100");
map.put("age", 10);
List<Monster> monsters = monsterMapper.findMonsterByName_Trim(map);
for (Monster monster : monsters) {
System.out.println("monster = " + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 7.2.7 set 标签应用实例【重点】
需求:请对指定 id 的妖怪进行修改,如果没有指定要修改的字段值,则保持原来的值
MonsterMapper.java
public interface MonsterMapper {
//根据 age 查询结果
public List<Monster> findMonsterByAge(@Param(value = "age") Integer age);
//根据 id 和名字来查询结果
public List<Monster> findMonsterByIdAndName(Monster monster);
//测试 choose 标签的使用
public List<Monster> findMonsterByIdOrName_choose(Map<String, Object> map);
//测试 foreach 标签的使用
public List<Monster> findMonsterById_forEach(Map<String, Object> map);
//trim 标签的使用
public List<Monster> findMonsterByName_Trim(Map<String, Object> map);
//测试 set 标签
public void updateMonster_set(Map<String, Object> map);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
MonsterMapper.xml
<!--
实现方法public void updateMonster_set(Map<String, Object> map);
原 SQL 语句:update monster set age = 10, email = 'xxx', name = 'xxx', birthday = 'xxx' ... where id = 3;
-->
<update id="updateMonster_set" parameterType="map">
update monster
<set>
<if test="age != null and age != ''">
age = #{age},
</if>
<if test="email != null and email != ''">
email = #{email},
</if>
<if test="name != null and name != ''">
name = #{name},
</if>
<if test="birthday != null and birthday != ''">
birthday = #{birthday},
</if>
<if test="salary != null and salary != ''">
salary = #{salary},
</if>
<if test="gender != null and gender != ''">
gender = #{gender},
</if>
</set>
where id = #{id}
</update>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
MonsterMapperTest.java
@Test
public void updateMonster_set() {
HashMap<String, Object> map = new HashMap<>();
map.put("id", 3);
map.put("name", "牛魔王2-100");
monsterMapper.updateMonster_set(map);
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("操作成功");
}
2
3
4
5
6
7
8
9
10
11
12
# 7.3 课后练习

# 第 8 章 映射关系一对一
# 8.1 基本介绍
项目中 1 对 1 的关系是一个基本的映射关系,比如:Person(人)--- IDCard(身份证)
# 8.2 映射方式
# 8.2.1 映射方式
(1)通过配置 XxxMapper.xml 实现 1 对 1【配置方式】
(2)通过注解的方式实现 1 对 1【注解方式】
# 8.2.2 配置 Mapper.xml 的方式-应用实例
(1)方式 1
通过配置 XxxMapper.xml 的方式来实现下面的 1 对 1 的映射关系,实现级联查询,通过 person 可以获取到对应的 idencard 信息
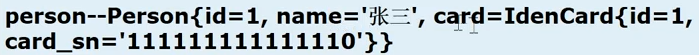
1)创建表:
-- 创建 person 表
create table person (
id int primary key auto_increment,
name varchar(32) not null default '',
card_id int,
foreign key (card_id) references idencard(id)
);
-- 创建 mybatis_idencard 表
create table idencard (
id int primary key auto_increment,
card_sn varchar(32) not null default ''
);
insert into idencard values (1, '11111111111110');
insert into person values (1,'张三',1);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2)创建 POJO、Entity
Person.java
package com.hspedu.entity;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/13 17:15
* @Description:
*/
public class Person {
private Integer id;
private String name;
//因为需要实现级联操作,card_id 是外键,每个人需要对应一个身份证,所以这里需要直接定义 IdenCard 对象属性
private IdenCard card;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public IdenCard getCard() {
return card;
}
public void setCard(IdenCard card) {
this.card = card;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
", card=" + card +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
IdenCard.java
package com.hspedu.entity;
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/13 17:13
* @Description:
*/
public class IdenCard {
private Integer id;
private String card_sn;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCard_sn() {
return card_sn;
}
public void setCard_sn(String card_sn) {
this.card_sn = card_sn;
}
@Override
public String toString() {
return "IdenCard{" +
"id=" + id +
", card_sn='" + card_sn + '\'' +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
3)创建接口和用于实现的配置文件
PersonMapper.java
public interface PersonMapper {
//通过 Person 的 id 获取到 Person,包括这个 Person 关联的 IdenCard 对象
public Person getPersonById(Integer id);
}
2
3
4
PersonMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.PersonMapper">
<!--
配置实现方法 public Person getPersonById(Integer id);
通过 Person 的 id 获取到 Person,包括这个 Person 关联的 IdenCard 对象【级联查询】
原 SQL:select * from person, idencard where person.id = 1 and person.card_id = idencard.id;
-->
<!--自定义 resultMap 搞定映射返回的结果-->
<resultMap id="PersonResultMap" type="Person">
<!--<result property="id" column="id"/>-->
<!--
id - 标记出作为 ID 的结果可以帮助提高整体性能
property="id" 表示 person 的属性 id,通常是主键
column="id" 表示对应表的字段
<result property="id" column="id"/> 可以写成
<id property="id" column="id"/> 用于提高整体性能
-->
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--
association 一个复杂类型的关联
property="card" 表示 Person 对象的 card 属性
javaType="com.hspedu.entity.IdenCard" 表示 card 属性的类型
property="id" 是属性名,column="id" 是字段名
-->
<association property="card" javaType="com.hspedu.entity.IdenCard">
<result property="id" column="id"/>
<result property="card_sn" column="card_sn"/>
</association>
</resultMap>
<select id="getPersonById" parameterType="Integer" resultMap="PersonResultMap">
select * from person, idencard where person.id = #{id} and person.card_id = idencard.id;
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
4)测试
PersonMapperTest.java
public class PersonMapperTest {
//属性
private SqlSession sqlSession;
private PersonMapper personMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
personMapper = sqlSession.getMapper(PersonMapper.class);
System.out.println("personMapper = " + personMapper.getClass());
}
@Test
public void t1() {
System.out.println("ok");
}
@Test
public void getPersonById() {
Person person = personMapper.getPersonById(1);
System.out.println("person = " + person);
if (sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
(2)方式 2
PersonMapper.java
public interface PersonMapper {
//通过 Person 的 id 获取到 Person,包括这个 Person 关联的 IdenCard 对象
public Person getPersonById(Integer id);
//通过 Person 的 id 获取到 Person,包括这个 Person 关联的 IdenCard 对象,方式2
public Person getPersonById2(Integer id);
}
2
3
4
5
6
PersonMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.PersonMapper">
<!--
配置实现方法 public Person getPersonById(Integer id);
通过 Person 的 id 获取到 Person,包括这个 Person 关联的 IdenCard 对象【级联查询】
原 SQL:select * from person, idencard where person.id = 1 and person.card_id = idencard.id;
-->
<!--自定义 resultMap 搞定映射返回的结果-->
<resultMap id="PersonResultMap" type="Person">
<!--<result property="id" column="id"/>-->
<!--
id - 标记出作为 ID 的结果可以帮助提高整体性能
property="id" 表示 person 的属性 id,通常是主键
column="id" 表示对应表的字段
<result property="id" column="id"/> 可以写成
<id property="id" column="id"/> 用于提高整体性能
-->
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--
association 一个复杂类型的关联
property="card" 表示 Person 对象的 card 属性
javaType="com.hspedu.entity.IdenCard" 表示 card 属性的类型
property="id" 是属性名,column="id" 是字段名
-->
<association property="card" javaType="com.hspedu.entity.IdenCard">
<result property="id" column="id"/>
<result property="card_sn" column="card_sn"/>
</association>
</resultMap>
<select id="getPersonById" parameterType="Integer" resultMap="PersonResultMap">
select * from person, idencard where person.id = #{id} and person.card_id = idencard.id;
</select>
<!--
方式二:将这个多表联查分解成单表操作
先通过 select * from person where id = #{id} 查询 person 的信息
再通过查询到的外键 card_id 的值,再执行操作得到 IdenCard 的数据
-->
<resultMap id="PersonResultMap2" type="Person">
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--
property="card" 表示 Person 对象的 card 属性
column="card_id" 这个是通过 select * from person where id = #{id} 查询到的 person 表的信息中的外键字段即 card_id
然后将查询到的字段 card_id 的信息作为 select="com.hspedu.mapper.IdenCardMapper.getIdenCardById" 的 getIdenCardById 方法的入参去调用这个方法
然后这个方法就可以拿着这个参数去 idencard 表里面找对应 id 的信息
-->
<association property="card" column="card_id" select="com.hspedu.mapper.IdenCardMapper.getIdenCardById"/>
</resultMap>
<select id="getPersonById2" parameterType="Integer" resultMap="PersonResultMap2">
select * from person where id = #{id}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
IdenCardMapper.java
public interface IdenCardMapper {
//根据 id 获取到身份证序列号
public IdenCard getIdenCardById(Integer id);
}
2
3
4
IdenCardMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.IdenCardMapper">
<!--
配置实现 public IdenCard getIdenCardById(Integer id);
-->
<select id="getIdenCardById" parameterType="Integer" resultType="IdenCard">
select * from idencard where id = #{id}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
PersonMapperTest.java
@Test
public void getPersonById2() {
Person person = personMapper.getPersonById2(1);
System.out.println("person2 = " + person);
if (sqlSession != null) {
sqlSession.close();
}
}
2
3
4
5
6
7
8
# 8.2.3 注解的方式实现-应用实例
通过注解的方式来实现 1 对 1 的映射关系,实现级联查询,通过 person 可以获取到对应的 IdenCard 信息,在实际开发中推荐使用配置方式
接口:PersonMapperAnnotation.java
public interface PersonMapperAnnotation {
//这里使用注解实现方法
//注解的形式就是对前面 xml 配置方式的另一种体现
@Select("select * from person where id = #{id}")
@Results({
@Result(id = true, property = "id", column = "id"),
@Result(property = "name", column = "name"),
@Result(property = "card", column = "card_id", one = @One(select = "com.hspedu.mapper.IdenCardMapper.getIdenCardById"))
})
public Person getPersonById(Integer id);
}
2
3
4
5
6
7
8
9
10
11
接口:IdenCardMapperAnnotation.java
/**
* @Author: 止束
* @Version: 1.0
* @DateTime: 2024/7/14 15:55
* @Description: 使用注解方式实现 1 对 1 的映射
*/
public interface IdenCardMapperAnnotation {
//根据 id 获取到身份证
//这个方法不需要返回任何级联对象
@Select("select * from idencard where id = #{id}")
public IdenCard getIdenCardById(Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
mybatis-config.xml 配置文件
<mapper class="com.hspedu.mapper.IdenCardMapperAnnotation"/>
<mapper class="com.hspedu.mapper.PersonMapperAnnotation"/>
2
测试:PersonMapperAnnotationTest
public class PersonMapperAnnotationTest {
//属性
private SqlSession sqlSession;
private PersonMapperAnnotation personMapperAnnotation;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
personMapperAnnotation = sqlSession.getMapper(PersonMapperAnnotation.class);
System.out.println("personMapperAnnotation = " + personMapperAnnotation.getClass());
}
@Test
public void getPersonById() {
Person person = personMapperAnnotation.getPersonById(1);
System.out.println("person = " + person);
if (sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 8.2.4 注意事项和细节
(1)表是否设置外键对 MyBatis 进行对象级联映射没有影响,即去掉 person 表的外键,依然可以获取相应的级联对象
# 8.3 课后练习
作业一:
(1)自己设计表 husband 和 wife,是 1 对 1 的关系
(2)通过查询 husband,可以级联查询得到 wife 的信息
(3)设计两张表:husband(id,name,wife_id)、wife(id,name)
作业二:
前面可以实现查询 Person 可以级联查询到 IdenCard,如果要求通过查询 IdenCard,也可以级联查询到 Person,即双向映射,该怎么办?
POJO、Entity:IdenCard.java
public class IdenCard {
private Integer id;
private String card_sn;
//通过查询 IdenCard 可以级联查询得到 person
private Person person;
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCard_sn() {
return card_sn;
}
public void setCard_sn(String card_sn) {
this.card_sn = card_sn;
}
@Override
public String toString() {
return "IdenCard{" +
"id=" + id +
", card_sn='" + card_sn + '\'' +
", person=" + person +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
接口:IdenCardMapper.java
public interface IdenCardMapper {
//根据 id 获取到身份证序列号
public IdenCard getIdenCardById(Integer id);
//根据 id 获取到身份证序列号,并查询级联的 person
public IdenCard getIdenCardById3(Integer id);
}
2
3
4
5
6
7
实现接口:IdenCardMapper.xml
<!--配置实现 public IdenCard getIdenCardById3(Integer id);-->
<resultMap id="IdenCardMapper3" type="IdenCard">
<id property="id" column="id"/>
<result property="card_sn" column="card_sn"/>
<association property="person" column="id" select="com.hspedu.mapper.PersonMapper.getPersonById3"/>
</resultMap>
<select id="getIdenCardById3" parameterType="Integer" resultMap="IdenCardMapper3">
select * from idencard where id = #{id}
</select>
2
3
4
5
6
7
8
9
调用的 Person 的方法
PersonMapper.java
//根据 card_id 查询相关信息,用于通过查询 IdenCard 时查询 IdenCard 的信息并且包括这个 IdenCard 关联的 Person 对象
public Person getPersonByCardId(Integer card_id);
2
PersonMapper.xml
<select id="getPersonByCardId" parameterType="Integer" resultType="Person">
select * from person where card_id = #{card_id}
</select>
2
3
测试:IdenCardMapperTest.java
@Test
public void getIdenCardById3() {
IdenCard idenCard = idenCardMapper.getIdenCardById3(1);
System.out.println("idenCard = " + idenCard);
if (sqlSession != null) {
sqlSession.close();
}
}
2
3
4
5
6
7
8
# 第 9 章 映射关系多对一
# 9.1 基本介绍
(1)项目中多对 1 的关系是一个基本的映射关系,多对 1,也可以理解成是 1 对多
(2)比如:User -- Pet:一个用户可以养多只宠物、Dep -- Emp:一个部门可以有多个员工
(3)这里直接讲双向的多对一的关系,单向的多对一比双向的多对一简单
(4)什么是双向的多对一的关系:比如通过 User 可以查询到对应的 Pet,反过来,通过 Pet 也可以级联查询到对应的 User 信息
(5)多对多的关系是在多对一的基础上扩展即可
# 9.2 映射方式
(1)方式 1:通过配置 XxxMapper.xml 实现多对 1
(2)方式 2:通过注解的方式实现多对 1
# 9.2.1 配置 Mapper.xml 方式应用实例
实现级联查询,通过 user 的 id 可以查询到用户信息,并可以查询到关联的 pet 信息,反过来,通过 pet 的 id 可以查询到 pet 的信息,并且可以级联查询到它的主人 user 的对象信息
插入数据表
-- 创建用户表
create table mybatis_user(
id int primary key auto_increment,
name varchar(32) not null default ''
);
-- 创建宠物表
create table mybatis_pet(
id int primary key auto_increment,
nickname varchar(32) not null default '',
user_id int,
foreign key (user_id) references mybatis_user(id)
);
insert into mybatis_user values (null, '宋江'),(null, '张飞');
insert into mybatis_pet values (1, '黑背', 1),(2, '小哈', 1);
insert into mybatis_pet values (3, '波斯猫', 2),(4, '贵妃猫', 2);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
创建实体Pojo、Entity 类
Pet
public class Pet {
private Integer id;
private String nickname;
//一个 pet 对应一个主人 user 对象
private User user;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
@Override
public String toString() {
return "Pet{" +
"id=" + id +
", nickname='" + nickname + '\'' +
", user=" + user +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
User
public class User {
private Integer id;
private String name;
//因为一个 user 可以养多个宠物,mybatis 使用集合体现这个关系
private List<Pet> pets;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Pet> getPets() {
return pets;
}
public void setPets(List<Pet> pets) {
this.pets = pets;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", pets=" + pets +
'}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
接口:
PetMapper.java
public interface PetMapper {
//通过 User 的 id 来获取 pet 对象,可能有多个,因此使用 List 接收
public List<Pet> getPetByUserId(Integer userId);
//通过 pet 的 id 获取 Pet 对象
public Pet getPetById(Integer id);
}
2
3
4
5
6
UserMapper.java
public interface UserMapper {
//通过 id 获取 User 对象
public User getUserById(Integer id);
}
2
3
4
配置文件实现接口:
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.UserMapper">
<!--
配置实现 public User getUserById(Integer id);
思路一:先通过 user 的 id 查询得到 user 的信息,再根据 user 的 id 与 user_id 对应查询到对应的 pet 信息并映射到 User 的 pets 属性中
-->
<resultMap id="UserResultMap" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--
因为 User 里的 pets 属性是集合,因此这里需要使用 collection 标签来处理
ofType="Pet" 指定 getPetByUserId 返回的集合中存放的数据类型是 Pet
-->
<collection property="pets" column="id" ofType="Pet" select="com.hspedu.mapper.PetMapper.getPetByUserId"/>
</resultMap>
<select id="getUserById" parameterType="Integer" resultMap="UserResultMap">
select * from mybatis_user where id = #{id}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
PetMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
(1) 这是一个 mapper xml 文件
(2) 该文件可以去实现对应接口的方法
(3) namespace 指定该 xml 文件和哪个接口对应
-->
<mapper namespace="com.hspedu.mapper.PetMapper">
<!--配置实现 public List<Pet> getPetByUserId(Integer userId);-->
<resultMap id="PetResultMap" type="Pet">
<id property="id" column="id"/>
<result property="nickname" column="nickname"/>
<association property="user" column="user_id" select="com.hspedu.mapper.UserMapper.getUserById"/>
</resultMap>
<select id="getPetByUserId" parameterType="Integer" resultMap="PetResultMap">
select * from mybatis_pet where user_id = #{userId}
</select>
<!--
配置实现public Pet getPetById(Integer id);
这里就体现出 resultMap 带来的好处,可以直接复用
-->
<select id="getPetById" parameterType="Integer" resultMap="PetResultMap">
select * from mybatis_pet where id = #{id}
</select>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
测试类:
UserMapperTest.java
public class UserMapperTest {
//属性
private SqlSession sqlSession;
private UserMapper userMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
userMapper = sqlSession.getMapper(UserMapper.class);
System.out.println("userMapper = " + userMapper.getClass());
}
@Test
public void t1() {
System.out.println("ok");
}
@Test
public void getUserById() {
User user = userMapper.getUserById(1);
System.out.println("user = " + user.getId() + " - " + user.getName());
List<Pet> pets = user.getPets();
for (Pet pet : pets) {
System.out.println("养的宠物信息 = " + pet.getId() + " - " + pet.getNickname());
}
if (sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
PetMapperTest.java
public class PetMapperTest {
//属性
private SqlSession sqlSession;
private PetMapper petMapper;
//编写方法完成初始化
//当方法标注 @Before,表示在执行目标测试方法前,会先执行该方法
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到 MonsterMapper 对象
petMapper = sqlSession.getMapper(PetMapper.class);
System.out.println("petMapper = " + petMapper.getClass());
}
@Test
public void getPetByUserId() {
List<Pet> pets = petMapper.getPetByUserId(2);
for (Pet pet : pets) {
System.out.println("pet信息 - " + pet.getId() + " - " + pet.getNickname());
User user = pet.getUser();
System.out.println("user信息 name = " + user.getName());
}
}
@Test
public void getPetById() {
Pet pet = petMapper.getPetById(2);
System.out.println("pet信息 = " + pet.getId() + " - " + pet.getNickname());
User user = pet.getUser();
System.out.println("user信息 " + user.getId() + " - " + user.getName());
if (sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 9.2.2 注解实现多对一映射 - 应用实例
通过注解的方式来实现下面的多对一的映射关系,实现级联查询,完成前面完成的任务,通过 User->Pet 也可 Pet->User,但在实际开发中推荐使用配置方式来做
接口:
UserMapperAnnotation.java
public interface UserMapperAnnotation {
//通过 id 获取 User 对象
/*
* (1) 注解的配置就是对应的 Mapper.xml 配置文件的改写
* <resultMap id="UserResultMap" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="pets" column="id" ofType="Pet" select="com.hspedu.mapper.PetMapper.getPetByUserId"/>
</resultMap>
<select id="getUserById" parameterType="Integer" resultMap="UserResultMap">
select * from mybatis_user where id = #{id}
</select>
* */
@Select("select * from mybatis_user where id = #{id}")
@Results({
@Result(id = true, property = "id", column = "id"),
@Result(property = "name", column = "name"),
//这里需要注意,pets 属性对应的是集合
@Result(property = "pets", column = "id", many = @Many(select = "com.hspedu.mapper.PetMapperAnnotation.getPetByUserId"))
})
public User getUserById(Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
PetMapperAnnotation.java
public interface PetMapperAnnotation {
//通过 User 的 id 来获取 pet 对象,可能有多个,因此使用 List 接收
/*
<resultMap id="PetResultMap" type="Pet">
<id property="id" column="id"/>
<result property="nickname" column="nickname"/>
<association property="user" column="user_id" select="com.hspedu.mapper.UserMapper.getUserById"/>
</resultMap>
<select id="getPetByUserId" parameterType="Integer" resultMap="PetResultMap">
select * from mybatis_pet where user_id = #{userId}
</select>
* */
@Select("select * from mybatis_pet where user_id = #{userId}")
@Results(id = "PetResultMap", value = {
@Result(id = true, property = "id", column = "id"),
@Result(property = "nickname", column = "nickname"),
@Result(property = "user", column = "user_id", one = @One(select = "com.hspedu.mapper.UserMapperAnnotation.getUserById"))
})
public List<Pet> getPetByUserId(Integer userId);
//通过 pet 的 id 获取到 Pet 对象,同时会查询到 pet 对象关联的 user 对象
/*
* <select id="getPetById" parameterType="Integer" resultMap="PetResultMap">
select * from mybatis_pet where id = #{id}
</select>
* */
//这里的 @ResultMap("PetResultMap") 意思是引用我们上面定义的 Results,即 ResultMap
@Select("select * from mybatis_pet where id = #{id}")
@ResultMap("PetResultMap")
public Pet getPetById(Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
测试类:
PetMapperAnnotationTest.java
public class PetMapperAnnotationTest {
//属性
private SqlSession sqlSession;
private PetMapperAnnotation petMapperAnnotation;
//初始化
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
petMapperAnnotation = sqlSession.getMapper(PetMapperAnnotation.class);
}
@Test
public void getPetByUserId() {
List<Pet> pets = petMapperAnnotation.getPetByUserId(1);
for (Pet pet : pets) {
System.out.println("宠物信息 - " + pet.getId() + " - " + pet.getNickname());
}
if(sqlSession != null) {
sqlSession.close();
}
}
@Test
public void getPetById() {
Pet pet = petMapperAnnotation.getPetById(1);
System.out.println("pet信息 = " + pet.getId() + " - " + pet.getNickname());
User user = pet.getUser();
System.out.println("user信息 = " + user.getId() + " - " + user.getName());
if(sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
UserMapperAnnotationTest.java
public class UserMapperAnnotationTest {
//属性
private SqlSession sqlSession;
private UserMapperAnnotation userMapperAnnotation;
//初始化
@Before
public void init() {
//获取到 sqlSession
sqlSession = MyBatisUtils.getSqlSession();
userMapperAnnotation = sqlSession.getMapper(UserMapperAnnotation.class);
}
@Test
public void getUserById() {
User user = userMapperAnnotation.getUserById(1);
System.out.println("user信息 = " + user.getId() + " - " + user.getName());
List<Pet> pets = user.getPets();
for (Pet pet : pets) {
System.out.println("宠物信息 = " + pet.getId() + " - " + pet.getNickname());
}
if(sqlSession != null) {
sqlSession.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 9.3 课后作业
(1)设计表 dept(部门)和 emp(雇员),是 1 对多的关系
(2)通过查询 dept,可以级联查询得到 emp 的信息
(3)通过查询 emp,可以级联查询得到对应的 dept 信息
# 第 10 章 缓存 - 提高检索效率的利器
# 10.1 一级缓存
# 10.1.1 基本介绍
(1)默认情况下,mybatis 是启用一级缓存/本地缓存/local Cache 的,它是 SqlSession 级别的
(2)同一个 SqlSession 接口对象调用了相同的 select 语句,会直接从缓存里面获取,而不是再去查询数据库
(3)一级缓存原理图
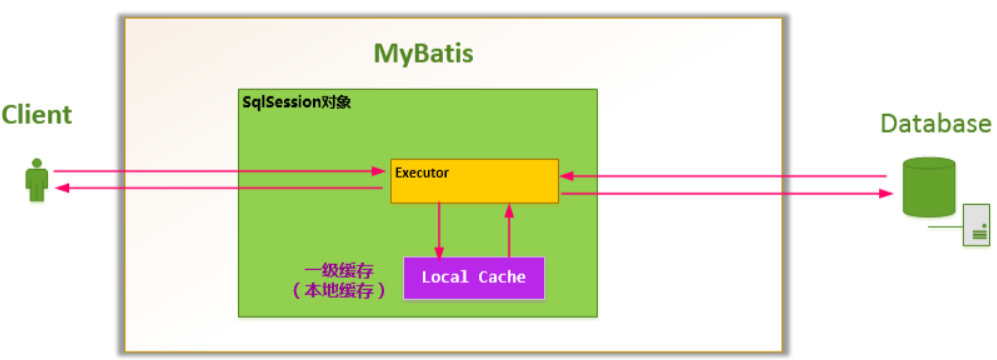
# 10.1.2 一级缓存
# 10.1.2.1 快速入门
需求:当我们第一次查询 id = 1 的 Monster 后,再次查询 id = 1 的 monster 对象,就会直接从一级缓存获取,不会再次发出 sql
(1)创建新的 Module:mybatis_cache
测试类 MonsterMapperTest.java
//测试一级缓存
@Test
public void level1CacheTest() {
//查询 id = 3 的
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster = " + monster);
//再次查询 id = 3 的
System.out.println("因为一级缓存默认是打开的,当你再次查询相同的 id 时,不会再发出 sql");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2 = " + monster2);
if (sqlSession != null) {
sqlSession.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 10.1.2.2 Debug 一级缓存执行流程
# 10.1.3 一级缓存失效分析
(1)关闭 sqlSession 会话后,再次查询会到数据库查询
(2)当执行 sqlSession.clearCache() 会使一级缓存失效
(3)当对同一个 monster 修改,该对象在一级缓存会失效
# 10.2 二级缓存
# 10.2.1 基本介绍
(1)二级缓存和一级缓存都是为了提高检索效率的技术
(2)最大的区别就是作用域的范围不一样,一级缓存的作用域是 SqlSession 会话级别在一次会话中有效,而二级缓存作用域是全局范围,针对不同的会话都有效
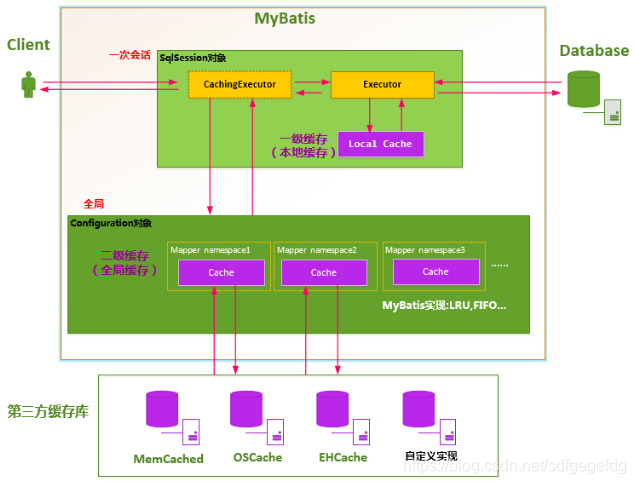
# 10.2.2 快速入门
(1)mybatis-config.xml 配置中开启二级缓存
<!--配置 MyBatis 自带的日志输出-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--全局性的开启或关闭所有映射器配置文件中已经配置的任何缓存
默认是 true
-->
<setting name="cacheEnabled" value="true"/>
</settings>
2
3
4
5
6
7
8
(2)使用二级缓存时 entity 类实现序列化接口(serializable),因为二级缓存可能使用到序列化技术

(3)在对应的 XxxMapper.xml 中设置二级缓存的策略
<!--
配置二级缓存
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。
如果我们只是用于读操作,建议设置成 true,如果有修改操作,设置成 false,默认就是 false
-->
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
2
3
4
5
6
7
8
9
# 10.2.3 注意事项和使用陷阱
(1)理解二级缓存策略的参数:
<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>
上面的配置意思如下:
创建了 FIFO 的策略,每隔 30 秒刷新一次,最多存放 360 个对象而且返回的对象被认为是只读的
其中:
eviction:缓存的回收策略
flushInterval:时间间隔,单位是毫秒
size:引用数目,内存大就多配置点,要记住缓存的对象数目和运行环境的可用内存资源数目,默认值是 1024
readOnly:true,只读
(2)四大策略
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
(3)如何禁用二级缓存
1)在 mybatis-config.xml 中将 <setting name="cacheEnabled" value="true"/> 的 value 值设为 false,这里是总开关
2)不配置二级缓存
3)在配置方法的时候指定设置 useCache=false 可以禁用当前 select 语句的二级缓存,即每次查询都会发出 sql 去查询,默认情况是 true,即该 sql 使用二级缓存

(4)mybatis 刷新二级缓存的设置
<update id="updateMonster" parameterType="Monster" flushCache="true">
update mybatis_monster set name=#{name},age=#{age} where id=#{id}
</update>
2
3
insert、update、delete 操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读,默认为 true,默认情况下为 true 即刷新缓存,一般不用修改
# 10.3 Mybatis 的一级缓存和二级缓存执行顺序
缓存执行顺序是:二级缓存 --> 一级缓存 --> 数据库
不会出现一级缓存和二级缓存中有同一个数据,因为二级缓存中的数据是在一级缓存关闭之后才有的
# 10.4 EhCache 缓存
# 10.4.1 基本介绍
(1)EhCache 是一个纯 Java 的缓存框架,具有快速、精干等特点
(2)MyBatis 有自己默认的二级缓存,但是在实际项目中,往往使用的是更加专业的第三方缓存产品作为 MyBatis 的二级缓存,EhCache 就是非常优秀的缓存产品
# 10.4.2 配置和使用 EhCache
(1)加入相关依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.hspedu</groupId>
<artifactId>mybatis</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>mybatis_cache</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--引入 EhCache 的核心库/jar-->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache-core</artifactId>
<version>2.6.11</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
</project>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
(2)mybatis-config.xml 仍然打开二级缓存,默认是打开的
(3)配置 ehcache.xml 配置文件,放在 resources 目录下
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="java.io.tmpdir/Tmp_EhCache"/>
<!--
defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。
-->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统宕机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
-->
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
(4)在 XxxMapper.xml 中启用 EhCache,这样原来的 MyBatis 自带的缓存配置就注销了
<!--配置/启用 ehcache-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
2
(5)测试
# 10.4.3 EhCache 缓存的细节说明
如何理解 EhCache 和 MyBatis 缓存的关系?
(1)MyBatis 提供了一个接口 Cache,只要实现了该 Cache 接口,就可以作为二级缓存产品和 MyBatis 整合使用,EhCache 就是实现了该接口
(2)MyBatis 默认情况(即一级缓存)是使用的 PerpetualCache 类实现 Cache 接口的,是核心类
(3)当我们使用了 EhCache 后,就是 EhCacheCache 类实现 Cache 接口的,是核心类
(4)发现缓存的本质就是 Map<Object, Object>
← SpringMVC SpringBoot →